OK, so you read my instructions on my previous post, and downloaded the appropriate bits from http://msdn2.microsoft.com/en-us/express/bb410792.aspx If you are planning to, are have already installed the Developer Edition, you only need to download the “Microsoft SQL Server 2005 Express Edition with Advanced Services” link. If you are only planning on doing the Express Edition, you’ll also want to download the link under it, “Microsoft SQL Server 2005 Express Edition Toolkit”. My instructions below only cover the database, not the toolkit.
OK, you’ve just downloaded the bits and it’s already time for the first “gotcha”. Before installing, you’ll want to make sure you have the IIS components installed on your machine. Odds are if you are an ASP.NET developer you probably already have them, but if not it’s a good idea to check.
In Vista, go to Control Panel, pick Programs and Features, then “Turn Windows Features on or off”. In the dialog that appears, scroll to Internet Information Services and expand the tree. Make sure all the items under “Web Management Tools” are checked. Now go down to “World Wide Web Services”. Under “Application Development Features” make sure .Net Extensibility, ASP.Net, and the ISAPI items are on. In “Common Http Features” check on everything but redirection. Everything under Health and Diagnostics should be on so you can log errors. Finally, under Security all you need on is Request Filtering.
XP is a little simplier. Under the control panel, Go to Add or Remove Programs, Add or Remove Windows Components. In the dialog that pops up, scroll down to Internet Information Services and check it. Click on details, and add FrontPage 2000 Server Extensions to what’s already checked. Then click OK a few times to get the updates installed.
In either situation, you may need your Windows disk handy to install the additional components.
OK, now you’re finally ready to run the setup. Double click on your sqlexpr_adv.exe to see this screen. All you have to do is check on the “I accept..” to accept the license agreement, then click Next.

Now SQL Server will check to see if it has everything it needs. This is the screen where it would yell at you if you didn’t have IIS installed. Since you do, just click Next.

Now we get a nice welcome screen. I’m feeling all warm and fuzzy now! Click next to continue.

Here SQL Server is going to make sure you have everything you need installed. If there is anything missing you should fix it before you proceed. If you get all greens, you’re good to go.

OK, here we need to deviate from the standard “next next next” default model a lot of us are used to. Make absolutely sure you UNCHECK the box you see below, “Hide advanced configuration options” We definitely want to see those advanced options.

Do you have it unchecked yet? If you don’t, you won’t get Reporting Services or Full Text Searching or the other cool features installed. Go ahead and fill out your name and company. Oh, and did I mention the box should be unchecked? If it is, like the screen below, you can click next.

OK, here we are on that advanced options screen. As you can see, all the cool toys are set to not install. Well that’s no fun. Go through each one and set it to install.

You can see below I have all the items checked on. I want to mention one thing. On the box I’m installing this on, I’ve already got the developer edition installed. So I don’t really need the Client Components. I’ve checked them on so I can show you something later. For now, click Next.

OK, here is your chace to give your server a name. Since everyone in the world uses SQLExpress, you should definitely not use it. Pick a name that’s logical, perhaps your computer name_express or computer_sql. Whatever you pick, change it now click Next.

Remember a few screens back when I said I was installing SQL Express on a machine that already had the Developer version installed? This is where it lets me know. The nice thing is the installer is smart enough not to choke. It simply says “Hey, I’ve already got this piece installed so I’ll skip it.” This is handy so you don’t have to think too much about the pieces you’re installing, you can pick everything and if it’s already there the installer will let you know then go on it’s merry way. Speaking of which, it’s time to get on our merry way by clicking Next.

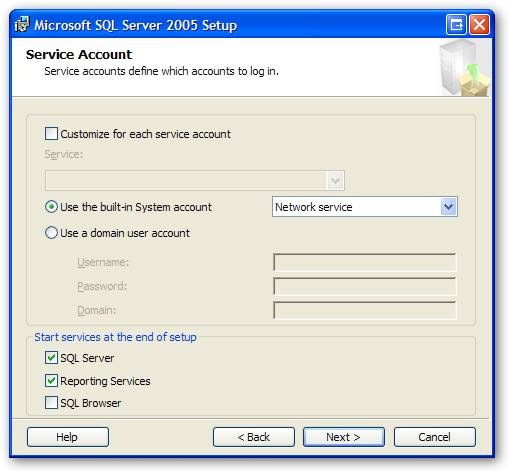
OK, now it wants to know a few things about how to run. First it wants to know what user id to run the service as. The default you see below will work just fine. Next it wants to what pieces it should run at startup. If you are going to be running this once in a blue moon, I would uncheck the SQL Server and Reporting Services options, then run them manually when you need them. On the other hand, if you are going to be in SQL Server nearly every day, like I am, it makes sense to leave these checked so they are started and ready for you. You’ll also want to leave these on if you are going to let other people connect to your box for testing reasons. Once you make your choices, pick Next.

OK, here SQL Server wants to know how you are logging into the server. DO NOT click next. Instead look at the next screen shot.

I don’t like using strictly windows authentication. Instead I much prefer using Mixed Mode. Pick it, then enter a password you can use for the sa account. I prefer this method as it gives me a little flexibility on how to use the database. Make sure you pick a password you’ll remember! Enter it and yes, you guessed it, click next.

Next it’s asking how you want SQL Server to sort text. I always take the default here, and click next. If you have special sorting needs you can change this, but odds are you can click next too.

This next screen is another one of those “Gotchas”.

This is really important to check on, so you can easily administer your own database. Check it on so it looks like the screen below, and hit next.

OK, time for another important question. You can install Reporting Services using the default config, or you can install but not configure now. The idea behind this was to allow you to install but not configure, then copy the configuration from another existing server. This is ideal for the enterprise where we are setting up one server after another and want them all to be identical. However, for our workstation we can simply install using the default configuration, and hit next.

Here Microsoft would like your help. Any data Microsoft can gather about SQL Server will help make it a better product. In some small way you’ll be contributing to the next version. However, I do recognize there are some people or shops that are wary of anonymous statistics gathering. I turned it on for my install, but if you have any doubts leave it off like I show below. Once your decision is made, click Next.

It’s finally time to begin the install. SQL Server shows you your choices one last time, and gives a big “are you sure”. You are, so just hit next.

OK, go get us a couple of cups of coffee, we’ll sit here and wait a bit. This screen will keep us updated on the install process.

As things are completed, they turn green, as you see here. When everything is installed, the Next button will become enabled. Click it to proceed.

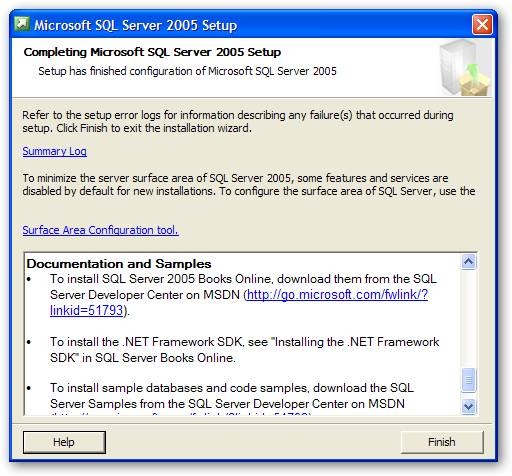
This is the last screen of the install, but don’t blow it off casually. It has some good info. Scroll the message window down to the bottom, as you see here, and you’ll find some good links. First, as you see on the screen, is a link to the Books on Line. You should download these and install them, they will become an often referenced companion and you learn SQL Server. Below that (just off the screen) are links to sample databases. If you are installing on a developer workstation and have the space, you should seriously consider installing these. Many, many authors (including myself, so you’ve been warned) will use these as material for their articles and samples. If nothing else it is very informative to see how Microsoft created a database.

That completes our installation of SQL Server Express with Advances Services. But the fun is just beginning…