Introduction
Seeing cumulative totals on a row by row basis is a common need. Think of your bank account, when you look at your ledger it shows each individual transaction. Beside each individual transaction is the current amount in your account, as offset by the amount of the current transaction.
This technique is known as cumulative sums. The Kusto Query Language provides the ability to create cumulative sums using the Windowing Function, row_cumsum. In this post we’ll see how to implement it.
First though, if you’ve not read the introductory post on Windowing Functions, Fun With KQL Windowing Functions – Serialize and Row_Number, you should do so now as it introduced several important concepts needed to understand how these Windowing Functions work.
The samples in this post will be run inside the LogAnalytics demo site found at https://aka.ms/LADemo. This demo site has been provided by Microsoft and can be used to learn the Kusto Query Language at no cost to you.
If you’ve not read my introductory post in this KQL series, I’d advise you to do so now. It describes the user interface in detail. You’ll find it at https://arcanecode.com/2022/04/11/fun-with-kql-the-kusto-query-language/.
Note that my output may not look exactly like yours when you run the sample queries for several reasons. First, Microsoft only keeps a few days of demo data, which are constantly updated, so the dates and sample data won’t match the screen shots.
Second, I’ll be using the column tool (discussed in the introductory post) to limit the output to just the columns needed to demonstrate the query. Finally, Microsoft may make changes to both the user interface and the data structures between the time I write this and when you read it.
Row_CumSum Basics
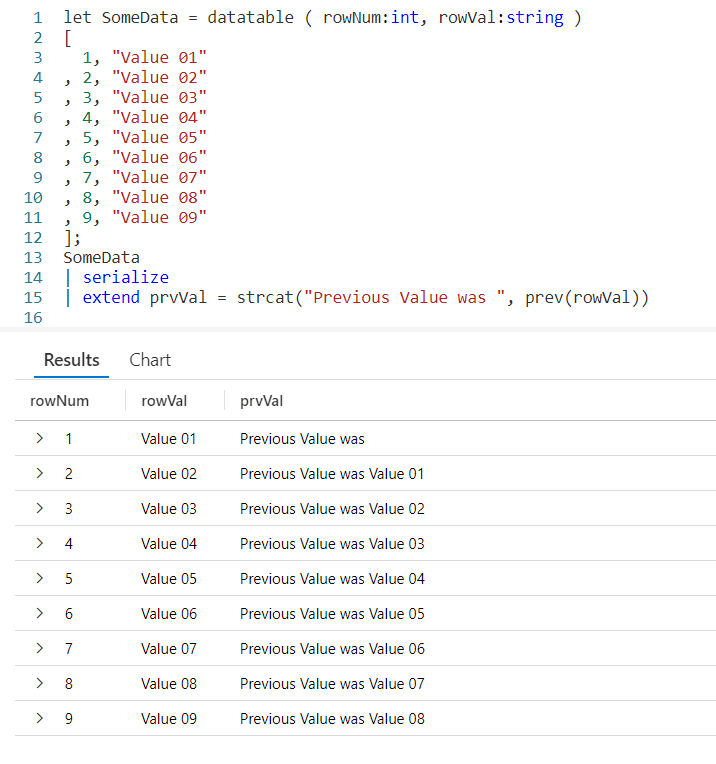
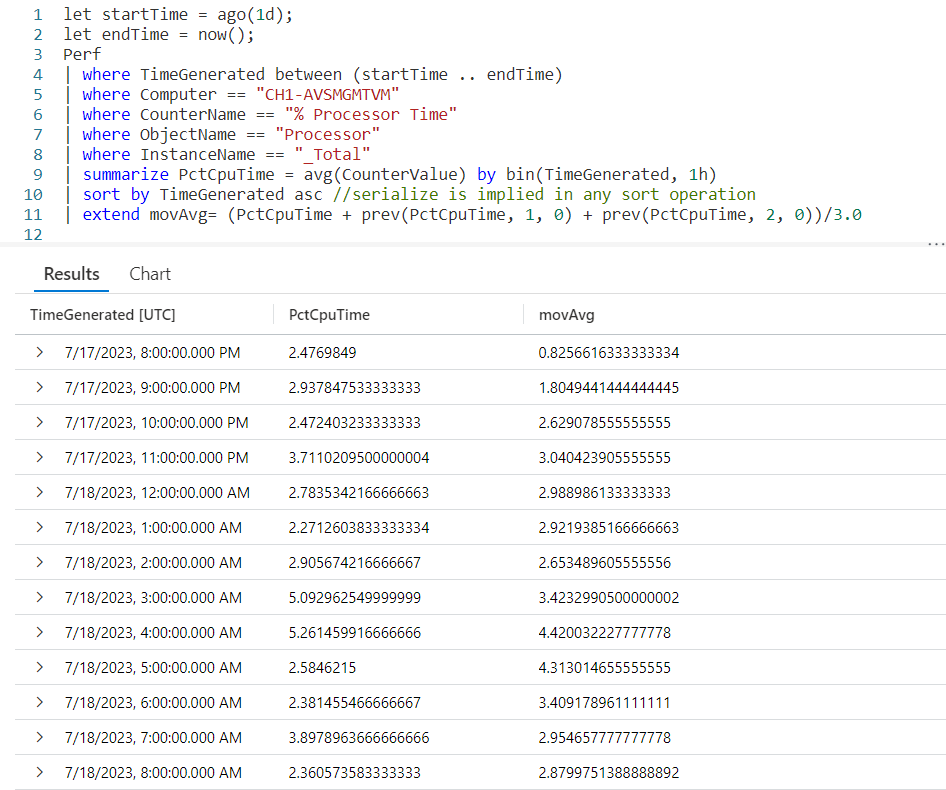
For this example I’ll be using let to generate a simple dataset using the datatable operator. It will have two columns, the row number rowNum, and a value rowVal. For more information on let, datatable, serialize, and other functions used in this post refer to the See Also later in this post.
Using row_cumsum is simple. First, we need to pipe the dataset SomeData into a serialize so we can use it with Windowing Functions. The serialize also lets us create a new column we named cumSum, and set it equal to the row_cumsum output. As a parameter, I pass in the numeric column I want to add up, here I used the rowNum column.

As you can see in row 1, the row number (rowNum) has a value of 1. There is no data since there are no previous rows, so it just returns 1.
In the second row, the value of rowNum is 2. The cumSum column already had a value of 1, so we’ll add 2 to it, for a result of 3.
With the third row, we’ll add the value in rowNum (3) to the value in cumSum (which also happened to be 3) and we’ll now have a cumulative sum of 6.
This repeats for each row, creating a cumulative summary.
You can also create a way to decrement the data by using a negative value for the row_cumsum parameter. For example, row_cumsum(rowNum * -1) could have been used to create a decrementing value much as spending money out of your checking account would decrement your balance. You’d just want to determine the best way to handle the beginning value (first row) of the dataset.
Resetting the Cumulative Counter
It’s possible you may not want to keep accumulating for all rows, but instead only have the accumulation for a group of rows. A common task is to reset the sum when a computer name changes, or perhaps the calendar month.
For this example, I’ve added a third column to our datatable, rowBucket. Whenever the value in rowBucket changes, I want to reset the cumulative sum value.

The row_cumsum supports a second parameter that is a boolean value. When true, the counter resets. Here, I’m using an equation to calculate “is the current rows rowBucket value not equal to the one from the previous row”. If this is true, in other words not equal, then the counter will reset.
Sure enough, on row 4 the rowBucket changed to 2. On this row the cumulative sum reset itself. It now keeps adding up until the bucket number changes again, as it does with row 6.
A Real World Example
Using a datatable made the examples easy to understand, but it’s time to look at an example you might want to use in the “real world”.
Let’s imagine a scenario where you’ve detected a large amount of network traffic coming from one of the computers on your Azure network. You’d like to check the performance log table (Perf) to see how many bytes each computer sent in the last five minutes.
You need to see the number of bytes sent by a computer for each log entry, but you also want to see the total bytes sent by a computer for that time period. Let’s look at a query to accomplish this goal.

We begin with our old buddy the Perf table. A where will limit the data to the last five minutes. A second where will limit the counter to just the one we are interested in, Bytes Sent/sec. Since we only need to see this data when the virtual Azure server sent data, we’ll add a final where to remove any rows where the CounterValue is zero.
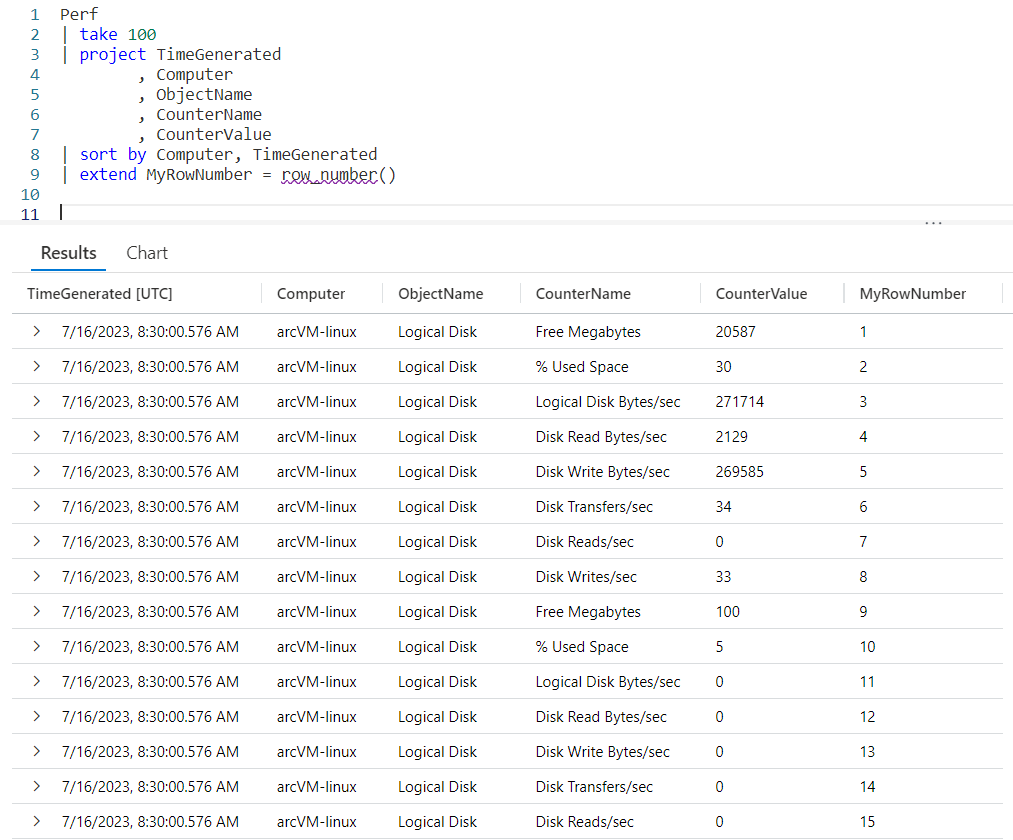
Next, we’ll use a project to strip down the columns to only the three we are interested in: the Computer, TimeGenerated, and CounterValue.
We then want to use a sort, so the data for each computer will be grouped together, then within a Computer the time the performance data was generated. Note that since the default for a sort is descending order, an asc was added after the TimeGenerated so the entries would go from the oldest to the most recent.
I normally might include an asc after the Computer so the computer names would be sorted alphabetically from A to Z, but left it off for this example just to remind you that with a sort you can mix and match the asc and desc columns.
Using a sort has another benefit. If you did go back and read my post Fun With KQL Windowing Functions – Serialize and Row_Number as I suggested in the introduction, you’ll know that the sort marks a dataset as safe for serialzation. In order to use Windowing Functions, such as row_cumsum and prev, a dataset needs to be safe for serialization.
The final line of the query is where the magic happens. Since using sort eliminated the need to use serialize, we can just use an extend to create a new column. I chose to name it cumulativeBytes.
We assign it the output of our row_cumsum Windowing Function. In the first parameter we pass in the CounterValue. In the second column we create an expression that will evaluate to true or false. We compare the Computer column for the current row and call the prev Windowing Function to get the Computer from the previous row of data.
If they are not equal, then the equation returns true. This will cause the row_cumsum to reset the cumulative sum.
Looking at the output, you can indeed see that occurred. The first computer in the list is CH1-VM-CTS. With each row it begins accumulating the CounterValue into the cumulativeBytes column.
When the Computer changed to CH-DMAVM, you can see the cumulativeBytes counter was reset. It kept accumulating the values for CH-DMAVM until the Computer changed to CH-AVSMGMTVM at which point it was again reset, and the pattern continues.
See Also
The following operators, functions, and/or plugins were used or mentioned in this article’s demos. You can learn more about them in some of my previous posts, linked below.
Fun With KQL Windowing Functions – Prev and Next
Fun With KQL Windowing Functions – Serialize and Row_Number
Conclusion
Cumulative sums are not an uncommon need when retrieving data. Kusto provides this ability with the Windowing Function row_cumsum, which you saw how to use in this post.
Our next post will continue the coverage of Kusto Windowing Functions by looking at the row_rank_min function.
The demos in this series of blog posts were inspired by my Pluralsight courses on the Kusto Query Language, part of their Kusto Learning Path.
There are three courses in this series so far:
I have two previous Kusto courses on Pluralsight as well. They are older courses but still valid.
These are a few of the many courses I have on Pluralsight. All of my courses are linked on my About Me page.
If you don’t have a Pluralsight subscription, just go to my list of courses on Pluralsight. On the page is a Try For Free button you can use to get a free 10 day subscription to Pluralsight, with which you can watch my courses, or any other course on the site.