
Introduction
In an earlier post in this series, Fun With KQL – Count, you saw how to use the count operator to count the number of rows in a dataset.
Then we learned about another operator, distinct, in the post Fun With KQL – Distinct. This showed how to get a list of distinct values from a table.
While we could combine these, it would be logical to have a single command that returns a distinct count in one operation. As you may have guessed by the title of this post, such an operator exists: dcount.
The samples in this post will be run inside the LogAnalytics demo site found at https://aka.ms/LADemo. This demo site has been provided by Microsoft and can be used to learn the Kusto Query Language at no cost to you.
If you’ve not read my introductory post in this series, I’d advise you to do so now. It describes the user interface in detail. You’ll find it at https://arcanecode.com/2022/04/11/fun-with-kql-the-kusto-query-language/.
Note that my output may not look exactly like yours when you run the sample queries for several reasons. First, Microsoft only keeps a few days of demo data, which are constantly updated, so the dates and sample data won’t match the screen shots.
Second, I’ll be using the column tool (discussed in the introductory post) to limit the output to just the columns needed to demonstrate the query. Finally, Microsoft may make changes to both the user interface and the data structures between the time I write this and when you read it.
SecurityEvent
Before we begin, let me mention for this post we’ll move away from the Perf table and use a new one, SecurityEvent. This table is just what it sounds like. Every time an object in your Azure instance, such as a server, has a security related event it gets logged to this table.
The SecurityEvent table has data a bit better suited for demonstrating the dcount function. Plus by this point, assuming you’ve been following along in the Fun With KQL series, you’re probably tired of looking at the Perf table.
A Refresher on Distinct
As dcount is a combination of distinct and count, let’s take a moment to refresh ourselves on them. We’ll start with the distinct operator.
Distinct returns a single entry for the columns indicated, no matter how many times they occur in the dataset. Here’s a simple example, where we want a list of distinct values for the combination of the EventID and Activity columns.

Taking a look at the first row, we have the event ID of 4688 and activity value of "4688 – A new process has been created.". This combination of values could occur once, or one million times in the SecurityEvent table. No matter how many times this combination appears, it will only show up once in the dataset produced by distinct.
Combining Distinct with Count
In the opening I mentioned we can combine distinct with count to get a distinct count. In the example below, we’ll pipe our SecurityEvent table into a where to limit the data to the last 90 days.
Be aware this query is a little different from the previous one. Here we are getting a distinct set for the combination of the computer name and the event ID. In this result set a computer will have multiple events associated with it. Here is some example data that might output from the distinct, to illustrate the point.
| Computer Name | EventID |
|---|---|
| WEB001 | 4668 |
| WEB001 | 5493 |
| WEB001 | 8042 |
| WEB001 | 5309 |
| SQL202 | 0867 |
| SQL202 | 5309 |
The result of our distinct is piped into the summarize operator. In the summarize we’re using the count to add up the number of EventID entries for each computer.
Finally we use a sort to list our computer names in ascending alphabetical order.

Our first entry, AppBE00.na.contosohotels.com, had 20 events associated with it. The last entry, AppFE0000CLG, only had 9 security related events.
DCount Basics
While we got our results, it was quite a bit of extra work. We can make our code much more readable by using dcount.
In the example below, we’ll replace the two lines of code containing distinct and count, and condense it into a single line.
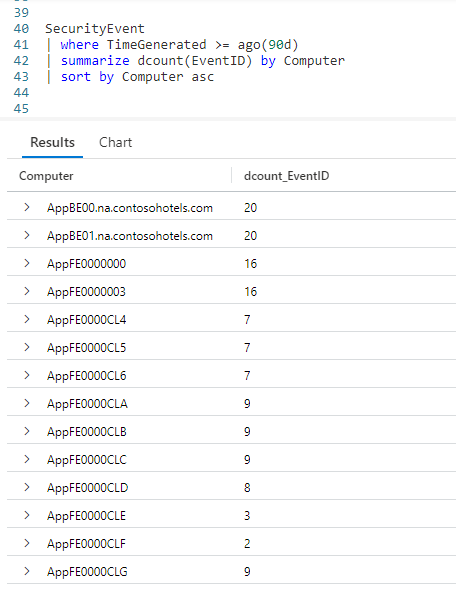
Here we use a summarize, followed by our dcount function. Into dcount we pass a parameter of the column name we want to count, in this case the EventID. We follow that with by Computer to indicate we want to sum up the number of distinct events for each computer name.
Speed Versus Accuracy (Don’t Skip This Part!!!)
There’s one important thing you have to know, and that is the count function can be slow. It has to go over every row in the incoming dataset to get the count, in a big dataset that can take a while.
The dcount function is much faster because it uses an estimated count. It may not be perfectly accurate, but will execute much faster.
Whether to use it is dependant on your goal. If you are trying to uncover computers with large numbers of events, it may not matter if AppBE00.na.contosohotels.com had 20 events, 19, or 21, you just need to know it had a lot (especially compared to other servers) so you can look at them.
On the other hand if you are dealing with, for example, financial data, you may need a very accurate value and hence avoid dcount in favor of the distinct + count combination.
Adjusting the Accuracy Level
The dcount function supports a second parameter, accuracy. This is a value in the range of 0 to 4. Below is a table which represents the error percentage allowed for each value passed in the accuracy parameter.
| Accuracy Value | Error Percentage |
|---|---|
| 0 | 1.6% |
| 1 | 0.8% |
| 2 | 0.4% |
| 3 | 0.28% |
| 4 | 0.2% |
An accuracy level of 0 will be the fastest, but the least accurate. Similarly, a value of 4 will be the slowest, but most accurate.
When the accuracy parameter is omitted, the default value of 1 is used.
Using the Accuracy Parameter
Here is an example of using the accuracy parameter. We’ll set it to the least accurate, but fastest level of 0.

As you can see, within the dcount after the EventID parameter we have a second parameter. We pass in a 0, indicating we want the fastest run time and will settle for a lesser accuracy.
Here is an example where we want a little better accuracy than the default of 1, and are willing to accept a longer query execution time.

As you can see, we are passing in a value of 2 for the accuracy parameter.
What Accuracy Value to Use?
So which value should you pick? As stated earlier, that’s dependant on your dataset and the goal of your query. If you are just taking a quick look and are OK with a rough estimate, you can use a lower value. Alternatively you can bump it to a larger value if you aren’t satisfied.
The best thing you can do is experiment. Run the query using each of the five values (0 to 4) and look at the results, deciding which best suits your needs for your particular goal.
See Also
The following operators, functions, and/or plugins were used or mentioned in this article’s demos. You can learn more about them in some of my previous posts, linked below.
Conclusion
In this post we learned how the dcount function can return a value faster than the combination of distinct plus count, although it may not be as accurate.
We then saw how we could adjust the accuracy level used in the dcount function, and got some advice on how to choose a level that balanced your need for speed with accuracy.
The demos in this series of blog posts were inspired by my Pluralsight courses Kusto Query Language (KQL) from Scratch and Introduction to the Azure Data Migration Service, two of the many courses I have on Pluralsight. All of my courses are linked on my About Me page.
If you don’t have a Pluralsight subscription, just go to my list of courses on Pluralsight . At the top is a Try For Free button you can use to get a free 10 day subscription to Pluralsight, with which you can watch my courses, or any other course on the site.
