Introduction
Often we want to get data that is relative to other data. For example, we want a list of computers that have free space that is greater than the free space of other computers. We need to set a threshold, for example we want to return results where the free space is greater than 95% of the free space on other computers.
To do this, Kusto provides the percentile operator, along with its variants percentiles and percentiles_array.
One hundred percent of the samples in this post will be run inside the LogAnalytics demo site found at https://aka.ms/LADemo. This demo site has been provided by Microsoft and can be used to learn the Kusto Query Language at no cost to you.
If you’ve not read my introductory post in this series, I’d advise you to do so now. It describes the user interface in detail. You’ll find it at https://arcanecode.com/2022/04/11/fun-with-kql-the-kusto-query-language/.
Note that my output may not look exactly like yours when you run the sample queries for several reasons. First, Microsoft only keeps a few days of demo data, which are constantly updated, so the dates and sample data won’t match the screen shots.
Second, I’ll be using the column tool (discussed in the introductory post) to limit the output to just the columns needed to demonstrate the query. Finally, Microsoft may make changes to both the user interface and the data structures between the time I write this and when you read it.
Percentile Basics
In this first example, we’ll use the percentile function to return a list of computers who have more than (or equal to) 90% of the free space of the other computers in the Perf table.

We take the Perf table and pipe it through a where to restrict the results to the Available MBytes counters.
This is piped into a summarize, where we employ the percentile function. In the first parameter we pass the column with the value to analyze, in this case it is the CounterValue column. In the second parameter, we pass in the threshold value, in this case 90.
Finally we use the by clause of summarize to indicate how we want to summarize the results. Here, we want to summarize by the ComputerName column.
In the results, we see a list of computers from the Perf table whose Available MBytes values are greater than or equal 90 percent of the other computers in the Perf table.
Do note, the Perf table actually represents a table of performance counter entries, so strictly speaking this isn’t totally accurate data. However we’ve been using the Perf table throughout this Fun With KQL series, so it will do for this example.
Percentiles Basics
The percentile function works fine for a single percentage, but what if you wanted to find values across a range of percentages? For example, you want to return values for 5, 50, and 95 percent?
Rather than having to run three different queries, Kusto provides a percentiles function so you can return multiple values at once.

The query is almost identical to the previous one, except we are using percentiles instead. As before the first parameter is the column to analyze. Next, we have multiple values to use for our percentile calculations.
Here we used three, 5, 50, and 95, however we could use just two, or more than just three.
At the end a sort by was used to order the output by the name of the computer.
In the output you see three columns for each computer, reflecting the Available MBytes values for 5, 50, and 90 percent.
Renaming The Output Columns
In the previous example the default column names that the percentile function output were rather, well ugly to put it bluntly. We could improve on it by using an operator we’ve seen before, project-rename.
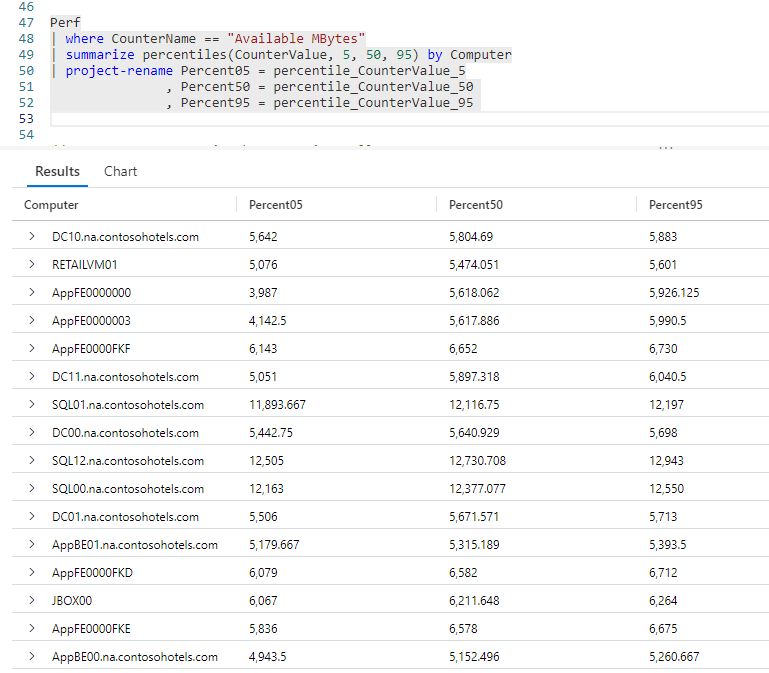
Our query is identical to the previous, except the sort by was replaced with project-rename. (The sort could have been retained, I simply removed it to make the example a bit simpler.)
If you recall my post Fun With KQL – Variants of Project, all we have to do is list each new column name we want to use, then after the equal sign the existing column to assign to it.
Our new names are a lot better, but we can streamline the rename process even more. The summarize operator allows us to rename when we make the call.

After the summarize operator we list each new column name we want to use for the output in parenthesis. As you can see, the output used the new column names we provided.
Multiple Levels of Percentiles
In the previous example, we used three percentiles, however this is no limit. In this next example we’ll bump it up to five.

Here we used the same technique as the previous sample, except we have more percentile values. As you can see, we also took advantage of KQL’s flexible layout to make the query easier to read.
Percentiles As An Array
There may be times when we want the percentiles returned in an array instead of columns. For that there’s an alternate version of the percentiles function, percentiles_array.

The first parameter passed into the percentiles_array function is the column we’re evaluating, here CounterValue. The remaining parameters are the percentile values to use. Here we used our original three, but we could have used as many as we needed.
We could call on our old friend mv-expand (covred in the post Fun With KQL – MV-Expand) to turn the expand the array into rows.

See Also
The following operators, functions, and/or plugins were used or mentioned in this article’s demos. You can learn more about them in some of my previous posts, linked below.
Fun With KQL – Variants of Project
Conclusion
In this post we saw how to use percentiles to evaluate data in relation to other data. We also saw how to return this data in array form.
The demos in this series of blog posts were inspired by my Pluralsight courses Kusto Query Language (KQL) from Scratch and Introduction to the Azure Data Migration Service, two of the many courses I have on Pluralsight. All of my courses are linked on my About Me page.
If you don’t have a Pluralsight subscription, just go to my list of courses on Pluralsight . At the top is a Try For Free button you can use to get a free 10 day subscription to Pluralsight, with which you can watch my courses, or any other course on the site.
